New APM Capabilities Help Optimize Application Performance Across Monoliths or Microservices
Splunk Observability recently announced several new enhancements to reduce noise and provide more visibility when isolating problems in your environments. Specific to applications and services, whether you operate monolithic or microservices architectures these releases help you easily investigate problems in complex environments.
Here’s a roundup of the recent Splunk APM capability releases.
Easily Identify Problems From Billions of Traces
Trace Analyzer helps to confidently detect patterns across billions of transactions and find specific issues for any tag, user, or service. Now you can identify unknown unknowns by running ad-hoc aggregations for all your trace data to find specific issues in any tag. Troubleshoot specific user issues by visualizing when patterns from errors and latency began and ended, and receiving the exact traces experienced during a problem. Understand the radius of an issue across customer groups by easily grouping and filtering high cardinality tags to scope a problem.

Trace Analyzer helps you quickly search and filter all of your trace data to find answers fast
Quickly Investigate Endpoint Performance
Engineers operating monolithic applications often struggle to identify problems across hundreds of endpoints. Splunk APM’s endpoint performance helps to easily explore and compare the performance of service endpoints. A centralized view shows the trends in latency and errors for all the endpoints, ranked by error rate or latency. Advanced filtering helps to quickly sort by common endpoint paths (/payment/ for example). When an issue occurs, quickly scope the impact of a problem by seamlessly navigating to APM’s troubleshooting flows or specific traces.
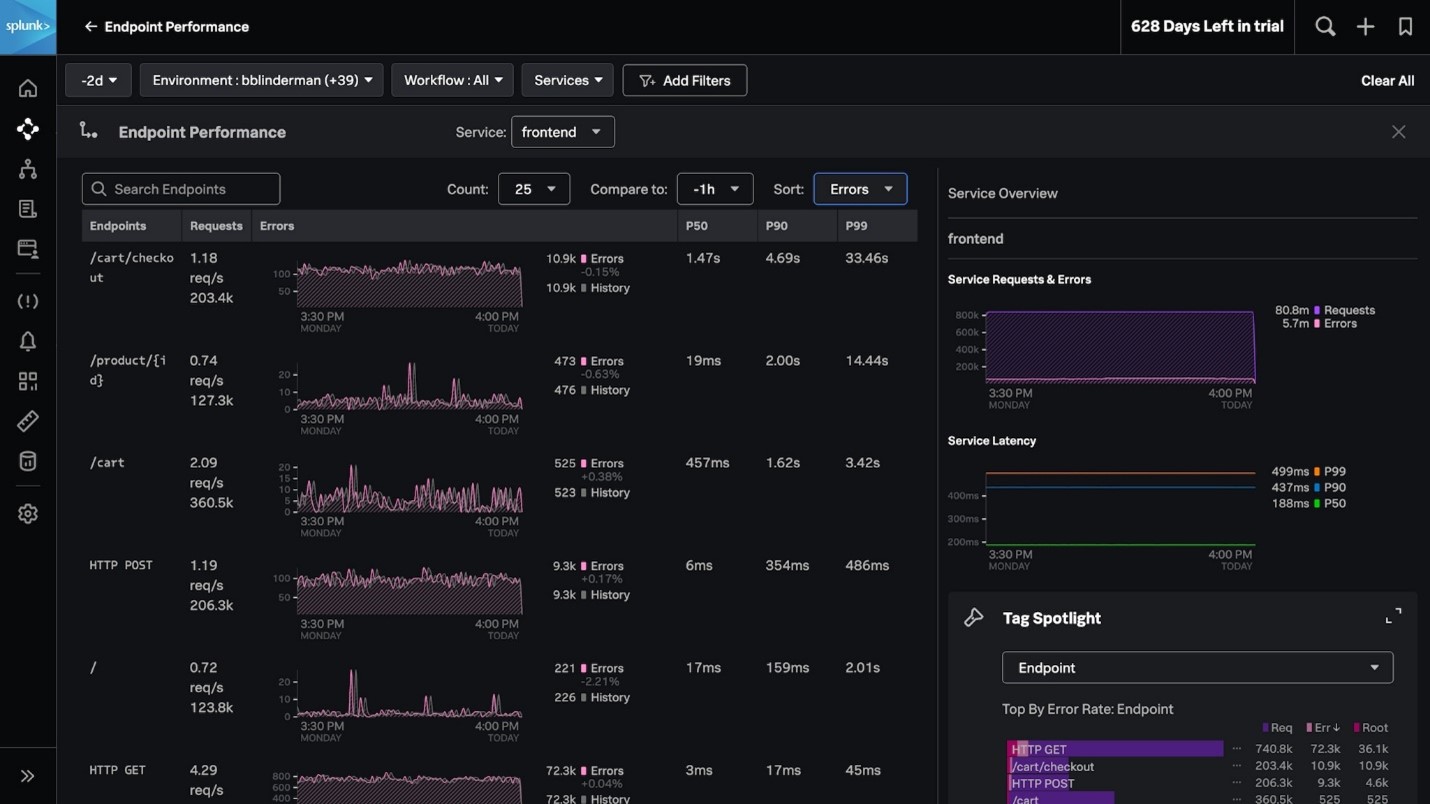
Quickly understand
the health and performance of your service’s endpoints
Improved Alert Accuracy, With Less Manual Effort
Autodetect uses machine learning to significantly reduce manual effort and improve accuracy for service alerts. Autodetect establishes performance baselines for every service, creates automatic detectors based on sudden changes in latency, errors, and request rates, and allows engineers to customize and subscribe to notifications for alerts on these detectors. As a result, engineers reduce time and effort in reconfiguring their alerts, and receive the most accurate alerting across cloud-native environments.

Autodetect uses ML to recommend alerts based on your application performance
Memory Profiling for .NET and Node.js Applications
AlwaysOn Profiling continues to expand language support, with memory profiling capabilities added for .NET and Node.js. Now engineers can continuously measure how their code impacts CPU and memory usage in .NET, Node.js, and Java applications, linked in context with all of their trace data to help identify problems, all with minimal overhead.

Reference: Splunk Blogs
A.K



Comments
Post a Comment